
みなさんこんにちは。dottの清水です。
前回の「肴を荒らさぬ町工場」では、「認知症ちえのわnet」に投稿される「ケア体験」のデータを自動分類する際に、データの量が少ないので戦術的にAIを作る必要があったというお話をしました。
今回は少ないデータを扱う場合に、どのように考えて、使用する人に都合の良いAIを作っていくかと言うお話です。
前回の話をまとめると、「ケア体験」という認知症のご本人のケア情報のカテゴリー分類を完全自動化できる枠組みは残しつつも、まだディープラーニングで学習するには少ない数のケア体験にも対応する必要がある、という内容でした。
データの中身を見てみると
まず「おきたことグループ」という400弱あるカテゴリーに、データがどのように存在しているか調査を行いました。
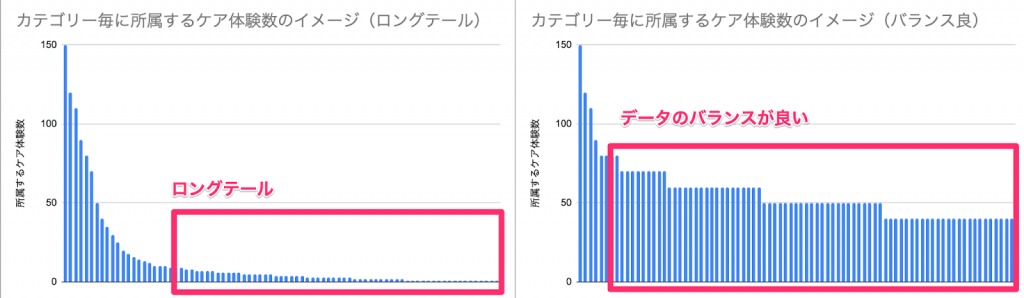
中身を見てみると、100件以上のケア体験が所属するカテゴリーもありましたが、1,2件のケア体験しかないカテゴリーが200件以上存在することがわかりました。発生した出来事の分類が専門的に細かく分かれるため、いくつかのカテゴリーにデータが集中し、その他は多くのカテゴリーに少ないデータが分散している、いわゆる「ロングテール」がある状態で、14%のカテゴリーに69%のデータが集中していました。
選択と集中
まずデータ件数が少ないカテゴリーの内容を再度見直し、他のカテゴリーと似ているものがないかを探し、可能なものは結合するという作業を行いました。これにより機械学習を行う最低ラインとして決めた「10件以上のデータがあるカテゴリー」は、全体のカテゴリーの14%から18%になり、カバーできるデータは69%から79%に上昇しました。
最低ラインを決める際は、実際に少ないカテゴリーに所属するデータを学習させ、それぞれのカテゴリー毎の精度を検証し、10件という数字が一つのボーダーになると考えたため、データの内容や分類するカテゴリーの多さ、AIをどう使うかによってもかなり差があると思います。
この方針により、全てのカテゴリーを対象にはできませんが、将来投稿されるデータの79%をカバーできると推測され、十分に実用的であるという判断となりました。
精度を克服する
さて、残る問題は精度です。
最低10件でも一つのカテゴリーを学習する、ということになったわけですが、BERTによるFine-tuningによる学習方法を用いても、とても心もとない数字です。
そこで僕たちdottの本分でもある、アプリケーション開発の力を使ってこの問題に取り組むことにしました。
まずAIを人間が作業する補助として利用する方針を固め、その上で作業効率の良いアプリケーションのインターフェースを実装することで、完全に自動化できなくても効率の良い状態になることを目指しました。
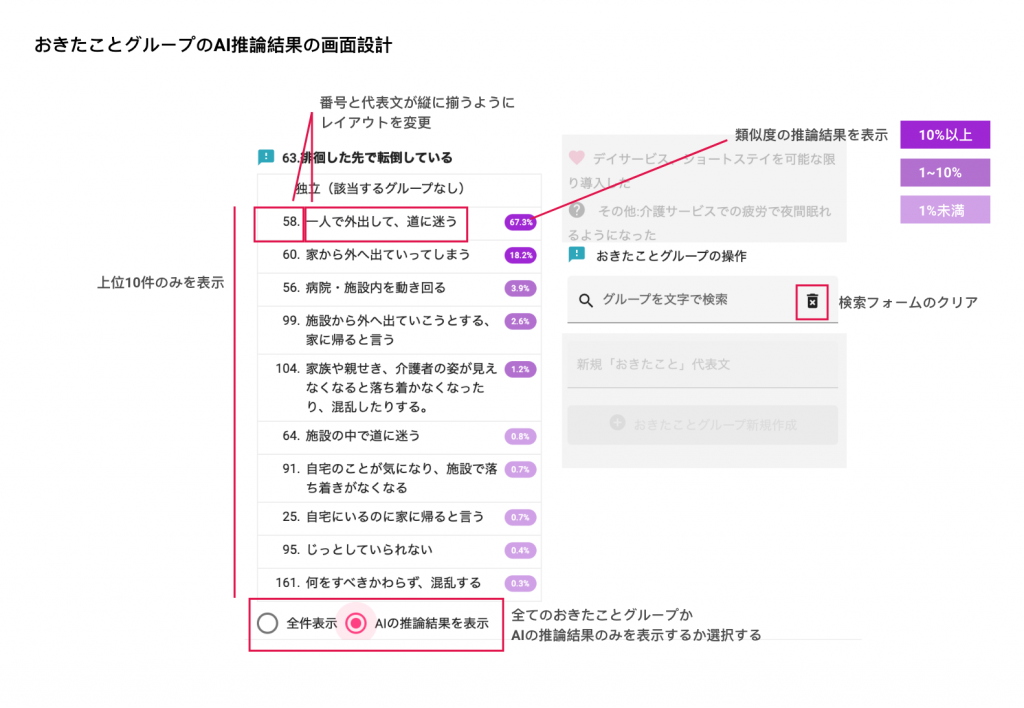
外と内の両方を設計する
このようなインターフェースを実装することにより、上位10件以内に正解のカテゴリーを推論することができれば、視覚的にもわかりやすく作業が行いやすくなります。最善の結果が出ていない状態のAIでも、このように用いる方法を考えることで活かすことができると考えています。
dottでは現実に即した形で、AIという粋な機能にいなせなインターフェースを実装するというアプリーケーションとAIの両方の視点から、最も効率的なAI開発を目指しています。
ただなんともまだデータが足りない感じがしますよね。
どうやってそれを克服したか、それはまた、次回の記事で。