Summary
手書き文字のOCR(Optical Character Recognition/Reader、オーシーアール、光学的文字認識)技術は特に日本語は難しいと言われています。
技術の進歩で精度はどんどん上がっていますが、現時点ではまだカスタマイズなしでプロダクトに使うのは厳しいレベルかなと言うのが我々の手書き文字OCRへの感想です。
この案件ではOCRによる手書き伝票と顧客DBのマッチングシステムを制作しました。OCRの精度を上げるアプローチではなく、OCRのミスの傾向を機械学習で分析し、マッチング精度を高める方向で実装しました。
一つの技術を突き詰めることも大事ですが、複数技術の組み合わせによってその時点での最適を目指す、という方向性がぴったりとハマった案件でした。
Technology
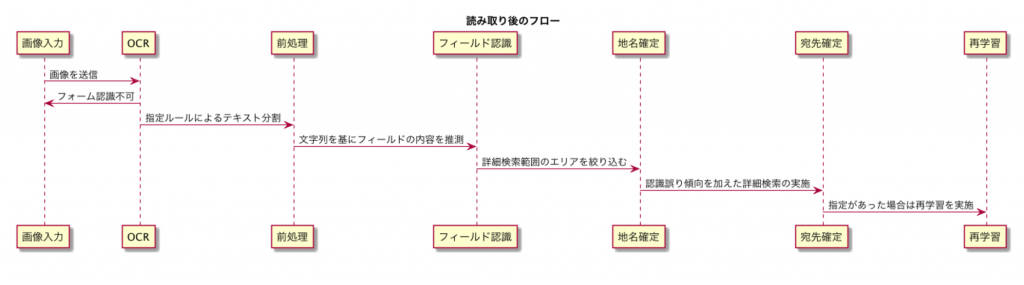
読み取り後の処理のフロー
住所部分のフローのみを紹介します。機械学習部分のアルゴリズムはrandom-forestを採用しています。このアルゴリズム自体は極めてシンプルで、複数の合致項目の妥当性の評価を行っていく形のものです(このアルゴリズムを使用したもので有名なのがアキネイターです)
大量の判定機とその正答傾向から答を推測するものとなりますが、入力時に文字単位での崩れが予想されるため、判定部分についてはそれを踏まえたアプローチを構築しています。