
みなさんこんにちは。dottの清水です。
第7回の「鯛で鯛を釣る」では、ビッグデータはディープラーニング的アプローチをするときに重要で、自分たちで作ろうとすると大変だという話をしました。特に人間が面倒だ手間だと感じる作業を自動化する訳ですから、人間の手で教師データを大量に作成すると言うのは、自分で自分の首を絞めるように辛いということに気づいたというところが前回までのハイライトでした。
今回はdottがAIに限らず自動化の仕組みを開発する際に大切にしている「作っている技術を使う」という考え方についてお話ししたいと思います。
必要なもの
本題に入る前に、ちょっとdottのML系プロジェクトの話を。
AI開発とかMLというと、何やら難しいニューラルネットワークの論文を読み、ネットワークを自分たちで実装し、様々な方法を検証してなんだかすごいものを作るようなイメージがありますが、dottはもっとカジュアルにやっています。
1%の精度を調整しながら100%の自動化を目指していくというよりも、現場で有効な解決方法を模索し、効果があるものから進んで投入するというような考え方です。
連載当初から何度か言ってきましたが、AIやディープラーニング自体を開発することが目的ではなく、下町の工場に相談が来る「現場での困りごと」を解決するために僕たちが用いる技術の一つ、それが「ディープラーニングだ」「AIだ」というスタンスです。
そしてdottでML系プロジェクトに入るメンバーに求めているのは、他の開発プロジェクトと変わらない「システムやアプリをテンポ良く実装する力」です。
黒船レオナルド
さて、前回レンゲの教師データをラベリングする時に「レンゲの位置さえ特定できれば、多くの種類のラベルをつけなくても良い」という話をしました。この話をもう少し具体的に掘り下げたいと思います。
前提を振り返ると、
- 「握らな寿司」のレンゲを画像から抽出する。
- どの種類の「握らな寿司」かを判定する。
- どれだけ食べられているか=完食率を判定する。
このようにレンゲの位置と寿司の種類、完食率をそれぞれラベリングする必要があったプロジェクトでした。そしてこの「握らな寿司」はプロジェクトのオリジナルの食事なので、自分たちで教師データとなる画像を撮影できるという前提条件もありました。
種類もさることながら、抽出した画像から完食率も画像で判定するという実験だったので、完食率を5段階に設定し、どの種類がどれだけ食べられているかというラベリングを行う必要があります。
種類や完食率を判定するためにはより多くの教師データが必要になりますが、レンゲを画像から抽出するだけの機能であれば、それほど多くの教師データがない状態でも判定できるようになります。その途中段階を「段階A」とします。
文字で説明する自信がないので、dottのAI、プロジェクトでも実際に活躍したレオナルド君に登場してもらいましょう。段階Aのレオナルド君はこんな状態です。
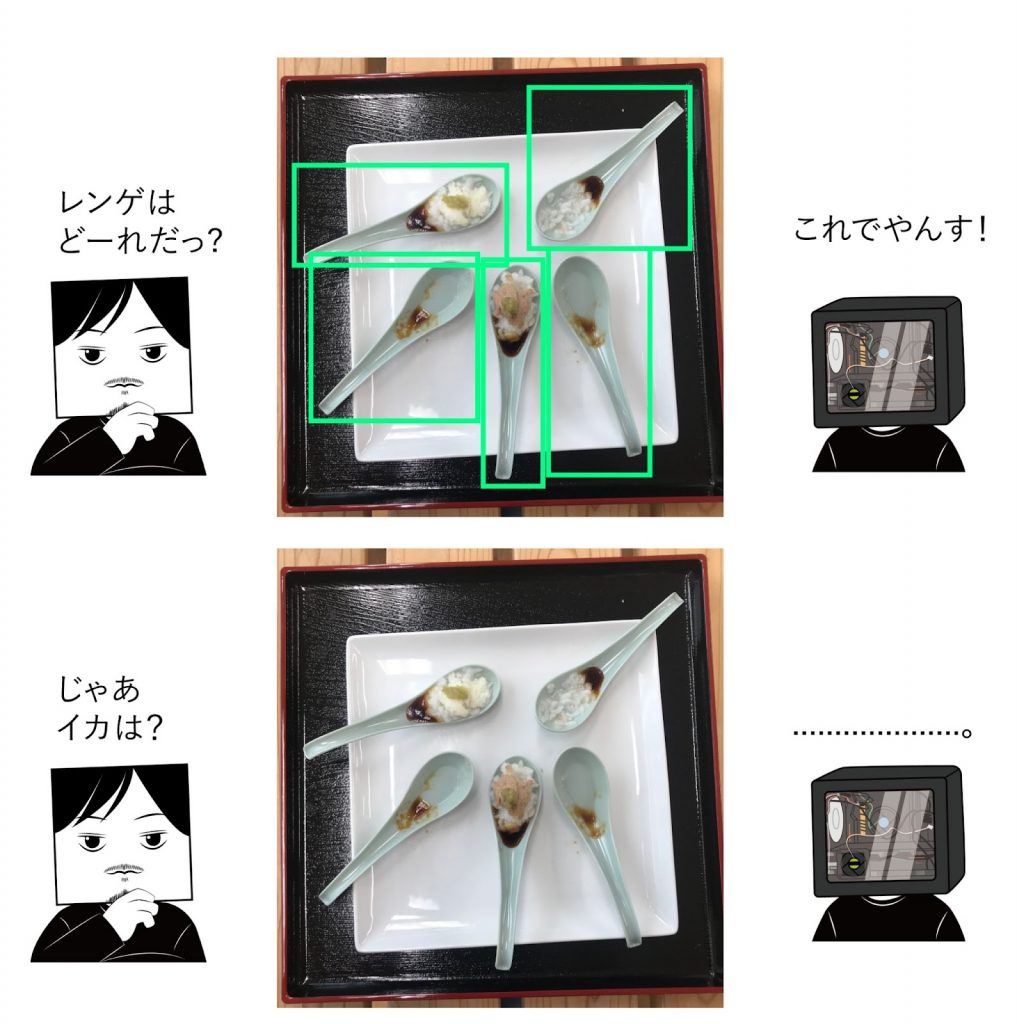
このように段階Aの状態では実証実験を行えるだけの精度を満たしていません。
しかしこの段階でも、レオナルド君は画像の中にあるレンゲの位置を特定できています。なのでこの状態のレオナルド君に、撮影時に記録した「どこに何があったか」を伝えると…。
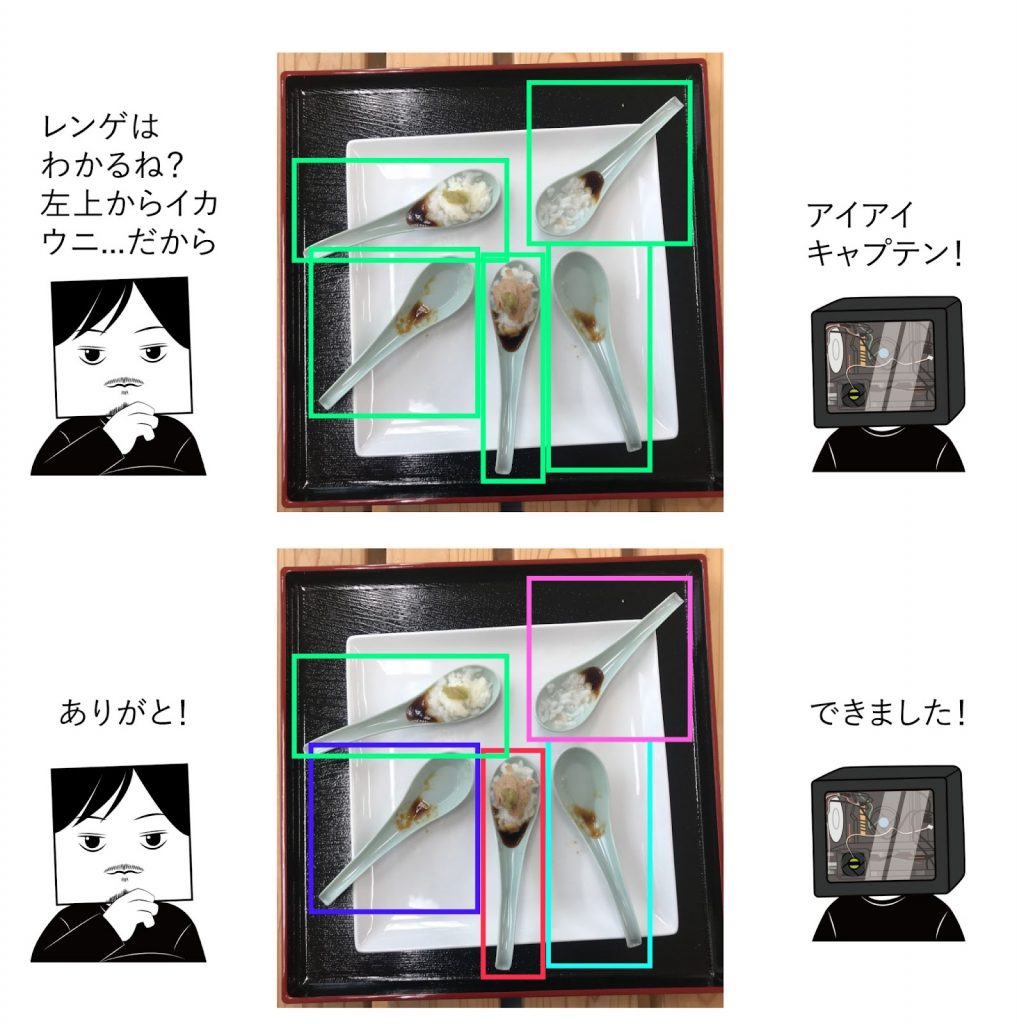
1種類しか検出することができないAIでも、教師データ側にあらかじめ情報を持たせて管理しておくことで、あとは半自動的にラベルを量産できるという流れです。
もっと具体的に言えば、フォルダ毎に寿司の種類と完食率を分けて、それがわかるようなフォルダ名をつけておき(「/sushi/13515/21423/」のように「/sushi/完食率/種類」を右上から順につけたもの)、あとは検出されたレンゲの位置とその番号を照らし合わせてラベリングが完了します。
AIの手も借りてぇよ
この方法が成功し、プロジェクトの残り少ない期間で大量の学習を終える事ができました。元々人の手で作業しようと思っていた残りのタスクの9割程度を、レオナルド君の力によってラベリングする事ができたというわけです。
すでに教師データとなるレンゲ画像の撮影は終わっていたのですが、上記のような手法でデータを整理するために再撮影を行ないましたが、それでも人間がラベリングするより遥かに短時間でタスクを完了することができました。
小さなことですが、このことはまるで江戸にやってきた黒船のように衝撃的で、人間がやる必要があると思っていた仕事を、AIが奪っていくという光景を自分たちの会社の中で見るとは想像していませんでした。
特にエンジニアが集まる集団の中では、少なくとももう少し先の未来の話だと思っていたという記憶があります。
この日をdottでは「AIが人間の仕事奪った日」と呼んでいます。
ちなみに僕は江戸も黒船も見たことはありません。
文明開化の音
このことから僕たちが受けた教訓は、手法自体というよりも、AIを作ろうとしている自分たちこそ、まずその恩恵を受けることができるという点です。
考え方は他のプロジェクトでも生かされており、データのラベリングなどを行うツールに自ら手を加えたり、アプリ自体を作ったり、作りかけのAIで作業を半自動化できないかということを常に考えています。
それはAIの問題や使用感を、テストではなく作業時の感覚として真っ先に技術者が体験できるという、効率化だけでなく質を高めていくための重要な方法だとも思っています。
ここでチームのメンバーに必要になってくるのが、冒頭に話した「システムやアプリをテンポ良く実装する力」というわけです。
これにて一件落着
4回にわたって連載してきた「SAWARABI HAPPY FOOD PROJECT」のレンゲの悪夢の話は、今回でおしまいです。
ディープラーニングの技術が多くの人の手により民主化されているからこそですが、自分たちはあくまで現場のラスト1mにツールを届けるため、UI・UX的な使いやすさの延長線上にあるものとしてAIを作っています。
GPUを積んだ黒船レオナルド君により、dottのディープラーニングの世界が幕を開けたのです。
他にも様々なプロジェクトでレオナルド君は活躍しますが、その話はまた、次回の記事で。