
みなさんこんにちは。dottの清水です。
第5回の「匙が通れば蓮華が引っこむ」では、2018年におこなわれた「SAWARABI HAPPY FOOD PROJECT」にて、画像からトレーの上に乗った「レンゲ」を抽出するためにOpenCVを使ったという話をしました。
そしてそのOpenCVを使った方法では成果が出ず、いよいよ困った僕たちは、当時リリースされて一年も経っていなかったくらいの「TensorFlow Object Detection API」を使う決断をしたところまでが前回のお話です。
今日はOpenCVよりも、TensorFlowを利用したレンゲの抽出がなぜ良かったのかという話をしたいと思います。
それは突然やってきて…
Object Detection APIというのは「Vision API」のように、WEB APIとして存在しているものではなく、TensorFlowを使って画像の中から特定の物体を検出するための機能です。
当然OpenCVで苦労したのと同じように、また相応の苦労が待っているのだと思っていました。しかし環境設定や慣れない内容に少し手間取ったくらいで、大量のレンゲのデータを学習させたところ、すぐにこんな成果が出ました。

OpenCVを使用した検出よりも、かなり「こうだったらいいな」という形で認識されていますね。

人類が抱える課題
レンゲの形をうまく学習することができましたが、これではまだ世界中の人々が苦しんでいる「レンゲ・スプーン問題」を解決できていません。
レンゲのみを学習していくと、当然モデルは「レンゲのようなもの」を検出することができるようになりますが、スプーンとの形の違いについてまだ知識がありません。
そのため僕たちはスプーンとレンゲの二つのものを学習させることで、この問題に対応しました。その結果がこちらです。

一部角度が大きくついたレンゲを検出できていませんが、スプーンとレンゲをうまく検知していることがわかります。このように使用するケースに合わせて学習する対象をうまくコントロールすることで「AIのラスト1m」という隙間を埋めて行くことができます。
感覚的な話ですが、OpenCVとTensorFlowの物体検知では、後者の方がより少ない労力でより良い成果が出たという印象があります。ローコストハイリターンです。
いったい、何が違うんです?
このシリーズ「下町ディープラーニング」では、技術的にややこしい説明を取り扱わないルールにしているので、ここではOpenCVとTensorFlowを用いた手法の違いについて、世界一大雑把な説明を目指してみます。
OpenCVで用いていたのは「カスケード分類」と呼ばれる機械学習の手法で、今となっては古典的ではありますが、昔から用いられてきた手法です。TensorFlowの方は「畳み込みニューラルネットワーク(CNN)」というディープラーニングを用いた手法です。
この二つは、画像の見方に違いがあります。
世界一大雑把な説明ができるように、大体のざっくりとしたイメージを図にしてみました。
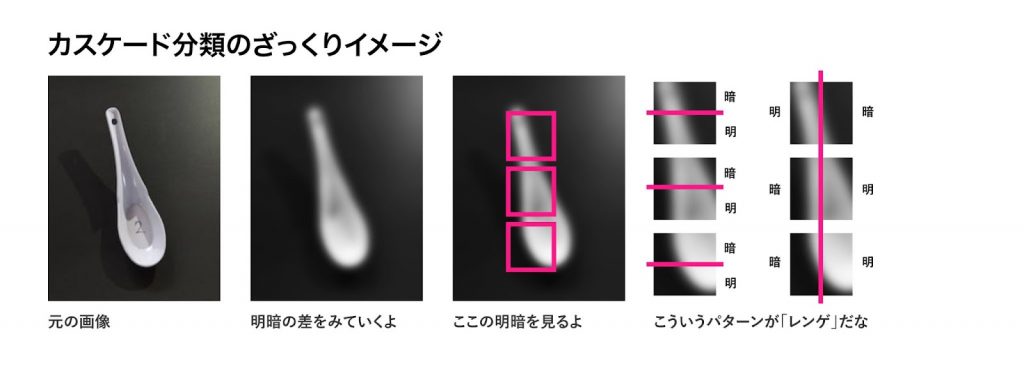
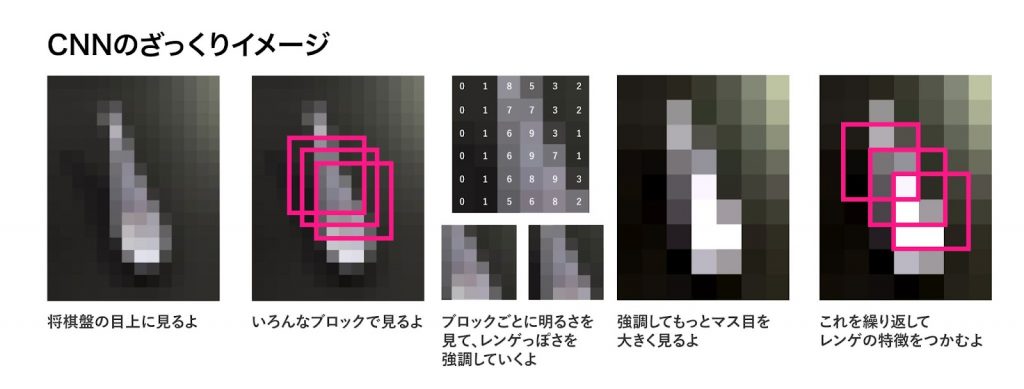
この画像で伝えたいことは
- カスケード分類の方は、局所的なブロックの明暗を縦横に見る。
- CNNの方は、ブロックのマス目ごとの特徴を見て、重ねて集めて(畳み込んで)いく。
という感じの内容です。
CNNでは細かい位置や大きさ、形や角度がより柔軟に判定されるため、形をより捉えやすく、レンゲとスプーンのくびれの違いなどもより理解しやすくなっているのだと思います。
カスケード分類の場合は角度や大きさの変化に対してとてもセンシティブだと感じました。一長一短はあると思いますが、どちらでやりたいかと聞かれたら、僕はディープラーニングによる物体検知だと答えるでしょう。
いいことばかりではないさ
ここまでの話では、全てが順風満帆に行っているように聞こえたと思います。
しかしディープラーニングを利用したシステムを開発する場合、おおよそ全ての人に訪れる困難は僕たちにも当然のように訪れます。
その話はまた、次回の記事で。